

Poisoning the Crypto Well
Replicating a $50 Million Crypto Hack and How It Can Be Stopped

$50 million was recently lost by a financial firm due to an address poisoning incident. The scale of the loss, combined with how straightforward this technique is to execute and how broadly it applies across digital asset operations (from stablecoins and tokenization workflows to sophisticated trading desks) makes it worth examining carefully.
What you should know at the outset:
This attack is relatively easy to perform, once the target victim wallet is identified. I was able to replicate the starting conditions of this attack on my local machine in hours for very little cost.
Later in this article I show how I replicated part of this process and estimate the compute cost at just $6.77.The attack relies on normal operational behavior, not cracking cryptography or breaching codebases.
In this piece, I’ll cover four things:
What happened in the December 2025 incident and how address poisoning works in practice.
Reading between the lines to construct a realistic operational scenario (such as those used by banks or hedge funds) that could plausibly lead to a loss like this.
How easy it is, walking through the underlying math and sharing empirical results from tests I ran locally to estimate feasibility, time, and cost at scale.
What can be done to mitigate the risk, with practical controls that address the root cause rather than the symptoms.
The goal is to demonstrate why this class of operational failure is more likely than many operators assume, and how it can be meaningfully reduced.
What Happened in the December 2025 Incident… and How Address Poisoning Works in Practice
Nothing in this incident involved breaking cryptography or exploiting a flaw in the blockchain itself. Instead, the loss resulted from exploiting a perfectly normal operational workflow… specifically, how humans and systems select and verify destination addresses under routine day-to-day operations.
In December 2025, approximately $50 million in USDT was transferred to the wrong Ethereum address in a single transaction. The funds were not stolen via a private-key compromise, a smart-contract vulnerability, or a protocol failure. Instead, the transaction was valid, signed by the rightful owner, and finalized on-chain exactly as intended: just to the wrong destination.
Public reporting on the incident indicates that the attacker address was crafted to match the same first three and last four hexadecimal characters as the legitimate destination (seven fixed character matches in total) making it visually indistinguishable under common address-verification practices.
The identity of the victim has not been publicly disclosed. Based on the size of the transfer, the operational patterns visible on-chain, and the nature of the assets involved, it is reasonable to infer that the victim was a financially sophisticated entity (such as a hedge fund/prop firm, exchange, prime broker, or other digital asset financial services firm).
The sequence of events, reconstructed from transaction history and typical operational patterns, appears to have followed a familiar path:
The victim had a history of sending funds to a specific destination address as part of routine operations.
A look-alike address (controlled by a malicious third party) was introduced into the victim’s transaction history through small, low-value transfers.
When a high-value transfer was later initiated, the sender selected or copied the malicious address from recent activity, mistaking it for the familiar destination.
The transaction was broadcast, confirmed, and irreversible. The funds were stolen.
This technique is commonly referred to as address poisoning. In practice, it exploits a gap between how blockchain addresses function and how humans verify them.
Reading Between the Lines: A Plausible Operational Scenario
To understand how a loss like the December 2025 incident can occur, it helps to step away from the idea of a single careless action and instead examine a reasonable, well-intentioned operational workflow… the kind commonly used by banks, hedge funds, exchanges, and other institutional digital asset operators.
Consider a simplified but realistic setup.
An organization maintains multiple wallets, each serving a distinct operational role. One wallet functions as an inbound or staging wallet. This is the address that receives assets from counterparties, exchanges, OTC desks, or internal entities. Its purpose is intake: assets arrive, undergo screening or internal checks, and are queued for onward movement. A second wallet (the trading or treasury wallet) is the destination where assets are consolidated once those checks are complete and where trading, hedging, or liquidity management actually takes place.
Funds move from the staging wallet to the trading wallet on a regular cadence. This might happen daily, multiple times per day, or whenever balances cross a threshold. The destination (the trading wallet) rarely changes.
Over time, this transfer path becomes familiar, routine, and operationally “safe.” The address is known. The pattern is known. Nothing about the workflow feels unusual.
It’s also worth noting why this workflow develops in the first place. Ethereum wallet addresses are long, opaque hexadecimal strings that are extremely difficult for humans to parse or compare in full. For example:
0x3fA9c1D8f31E8B6A9F0aB5E2F19f4c77B92e4A3F
As a practical matter, most operations teams do not (and realistically cannot) manually verify all 40 hexadecimal characters every time a transaction is prepared. Instead, teams often develop operational verification shortcuts, such as checking only the first and last few characters of the destination address (for example, the first three and last three).
From the outside, however, this consistency is visible on-chain.
A malicious third party observing activity can see that:
the staging wallet receives frequent inbound transfers, and
those inbound transfers are consistently followed by outbound transfers from the staging wallet to the same trading wallet, often within predictable time windows and for material amounts.
At that point, the trading wallet address becomes an obvious point of focus. It is the operational destination that matters.
Now imagine that, at some point, a new address appears in the staging wallet’s transaction history. It is introduced via a small, low-value transfer… an amount too insignificant to trigger alerts or disrupt balances.
However, the address itself is visually similar to the legitimate trading wallet address. Specifically, its beginning and ending characters closely match those of the real trading wallet, such that when abbreviated in a wallet interface, the two appear nearly identical.
For example, imagine the legitimate trading wallet address is:
0x3fA9c1D8f31E8B6A9F0aB5E2F19f4c77B92e4A3F
An address controlled by the malicious third party might look like this:
0x3fA1E8c0D92bA97F6E6C65A0B2d2e4B41E4A3F
When displayed in a typical wallet interface that truncates addresses, both may appear as something like:
0x3fA…A3F
Nothing forces immediate action. The staging wallet simply now has multiple historical interactions with addresses that look similar to the trading wallet.
Days or weeks later, an operations team member initiates a routine sweep from the staging wallet to the trading wallet. They review recent activity, copy a destination address from transaction history. The visible prefix and suffix match what they expect for the trading wallet. The transfer amount may be large, but the workflow itself is ordinary… one that has been executed many times before.
The transaction is signed and broadcast.
From the system’s perspective, everything functions correctly. The transaction is valid. The destination address exists. The network confirms it. Only afterward does it become clear that the funds were sent not to the intended trading wallet, but to a different address… one that appeared correct under partial visual inspection but was never part of the organization’s approved operational flow.
Crucially, nothing in this scenario requires negligence, poor security hygiene, or a breakdown in cryptographic controls. It arises naturally from:
reuse of a known destination address (the trading wallet),
reliance on transaction history within the staging wallet,
partial visual verification of long hexadecimal identifiers, and
the assumption that “looks familiar” is equivalent to “is correct.”
This is what makes the failure mode so dangerous. It does not rely on exceptional mistakes. It relies on normal operational behavior executed in an environment where those behaviors can be observed and anticipated.
How Easy Is The Attack? Feasibility, Time, and Cost
At a high level, the feasibility of this technique comes down to one question: how hard is it to generate an address that matches the few characters an operator actually checks in a manual approval workflow? The answer is unintuitive to many people, because the security of Ethereum addresses is often conflated with the difficulty of breaking cryptography. This problem is different. It is not about breaking anything… It is about matching patterns in a large, but uniformly random space.
The underlying math (at a glance)
Ethereum addresses (ignoring the 0x prefix) consist of 40 hexadecimal characters. Each character can take one of 16 possible values (0–9 and a–f). If we assume addresses are uniformly random (which is a good approximation) then the probability of matching a specific character in a specific position is simply 1 in 16.
If an operator verifies only some specific n characters of a destination address, then each maliciously generated address has a probability to match those n characters of:
probability = (1/16)^n
And translating this into the total number of attempts, it is just:
Expected attempts = 16^n
So, each additional character that a malicious attacker needs to match to the victim address multiplies the expected work by 16X.
Note that it does not matter if those matched characters are at the beginning, end or a combination of positions in the address for the expected attempts to be affected. It only matters that the attacker knows “which” characters need to be matched (e.g., the first and last 3 characters).
Replicating the attack on my machine
I wrote a very simple script to do exactly the attack outlined above… at least the portion of the attack that involves creating the malicious poisoning address (I won’t be sharing the script, as to not encourage anyone to carry out this attack, but the code is trivial).
Quick notes
I did this on a local machine: a Macbook with an M2 processor. Dead simple.
7 Character Matches would be similar to the attack we discussed earlier (3 character matches at the beginning and 4 at the end of the deposit address).
Here is what my results looked like compared to the theoretical values above:
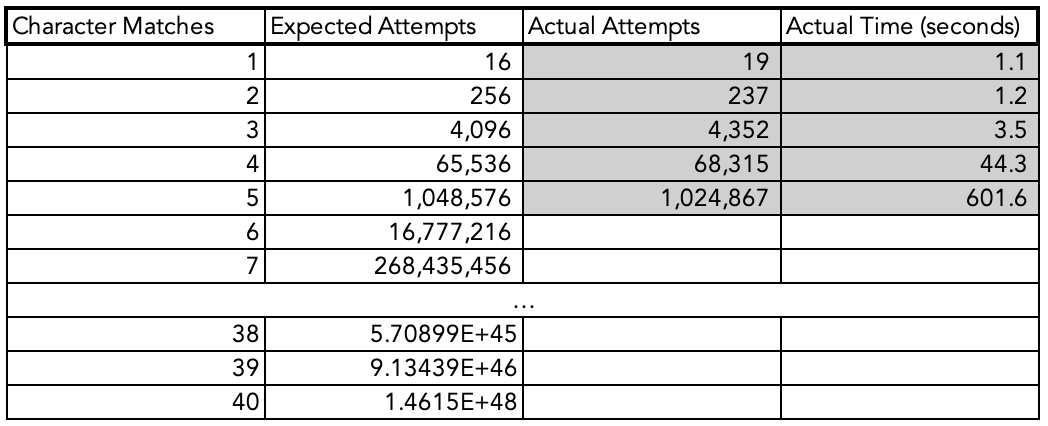
You can see that the Expected Attempts and Actual Attempts are very close to each other. Theory checks out with actuality.
For this illustration I stopped at 5 character matches, but you can observe from 4 to 5 character matches there was an increase of ~13.7X in time (44 seconds for 4 matches, and 601 seconds for 5 matches). This is close to the 16X expected time increase for each additional match. This is sufficient to prove the pattern and I didn’t want to wait around for 2.5+ hours for a 6 character match (let alone ~40 hours for a 7 character match) to be found and these results are conclusive enough.
Note for anyone that cares: the code used multiprocessing (8 threads).
Takeaway: if I can get a match on my local machine in hours, with little work put in to optimize the code beyond multithreading, then checking several characters in the destination address opens the door to easy address poisoning attacks.
How much would this attack cost the attacker?
To better understand the economics of this technique, I took the empirical runtimes from my local tests and asked a simple follow-up question: what would this look like at scale?
Using the observed time per match on my local machine, I estimated how long the same work would take if parallelized across a larger fleet. As a rough benchmark, I looked at the cost of renting machines with comparable performance to my laptop and asked: what would the cost and time look like if I ran this across 1,000 machines simultaneously?
I found a provider where a machine with similar specs would cost ~$3.80 a day. This is not the cheapest way to do this (far from it). More efficient architectures and less expensive cloud infrastructure would reduce costs materially. I chose this approach simply to keep the comparison roughly apples-to-apples with my local tests.
The cost that would correspond to the attack discussed at the beginning of this article would be the 7 Character Matches row. You can see that the estimated cost for this would be $6.77.
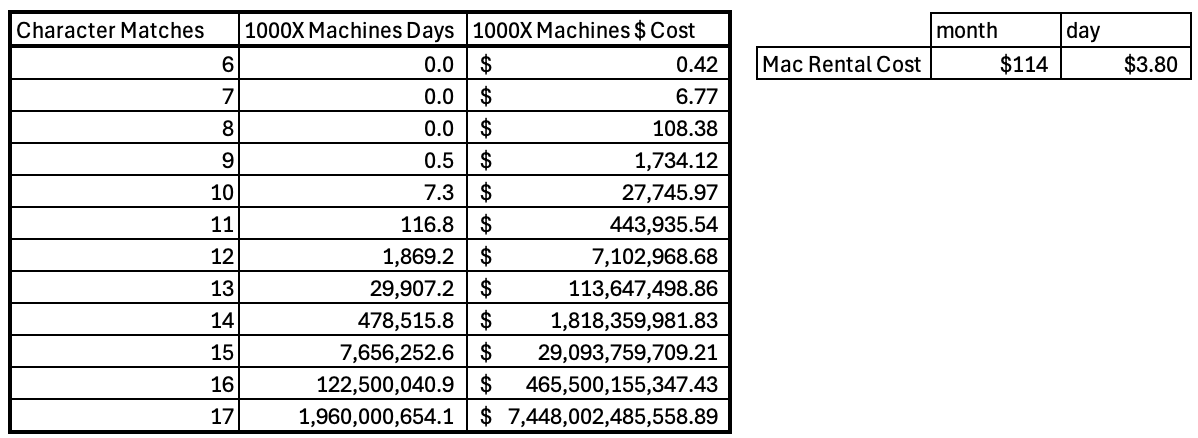
Even under these conservative assumptions, the results illustrate an important asymmetry.
For small numbers of required character matches, the cost remains modest and well within reach of commodity infrastructure. But because the required work grows exponentially, costs explode quickly as the number of required matches increases. By the time you approach ~17 fixed character matches, the implied cost runs into the trillions of dollars, quickly surpassing not just reasonable attacker budgets but even the total global supply of physical currency (M0).
At that point, time becomes irrelevant. Even with aggressive parallelization, you would likely run into physical and economic limits long before completing the search.
This observation is not meant to suggest that attackers will attempt to match dozens of characters. Quite the opposite. It highlights the uncomfortable reality that operators do not need to be “slightly wrong” for this to be dangerous. The attack becomes infeasible only at character counts beyond what humans/manual verification workflows tend to involve.
The implication is straightforward: below a certain threshold, the attack is cheap and practical. Above it, it becomes impossible. Many workflows operate on the lower side of that boundary.1
How Can This Risk Be Mitigated?
This risk highlights an important, and overlooked point in digital assets: the industry tends to view risks primarily at the cryptographic or “code bug” level. This risk is specifically addressed in the operational workflow design.
Effective mitigations fall into three broad categories: process controls, technical controls, and behavioral/UI controls. The strongest defenses combine all three.
1. Eliminate free-form destination selection for high-value flows
The most important control is also the simplest conceptually: do not allow arbitrary destination addresses for material transfers.
For institutional operators, this means enforcing destination allowlists at the policy level… not just saving addresses in a UI/spreadsheet contact list. Transfers above a defined threshold should only be permitted to pre-approved destination addresses, and any change to that list should require a separate approval process involving multiple parties.
Critically, allowlisting must be enforced by the system executing the transaction (custodian platform, policy engine, or smart contract), not merely documented in a runbook. If the system allows an operator to paste an address manually, the failure mode still exists.
Allowlists maintained within an environment like a Wallet Connector can suffice, but operational controls need to be in place to ensure things like multi-party approvals are a technical requirement and not just a conceptual workflow.
2. Separate “address approval” from “transaction execution”
A recurring theme in these incidents is that address verification and transaction execution happen in the same moment, often by the same person.
A safer pattern is to treat destination addresses as configuration, not input:
New destination addresses are introduced through a dedicated workflow.
That workflow includes independent review and approval.
Only after approval does the address become selectable for execution.
This separation ensures that address verification is not performed at the same moment as a high-value transfer.
3. Avoid transaction-history based address selection
Copying destination addresses from recent transaction history is a natural convenience feature, but it is also the primary surface exploited in address poisoning incidents.
For sensitive workflows:
Destination addresses should be sourced from a canonical internal registry, not wallet history. If wallet history is the source of a new destination address, then it should go through the defined “address approval” workflow (as all new addresses should).
Recent inbound or outbound interactions should never be treated as implicit validation.
Small unsolicited transfers should be treated as hostile noise.
If transaction history must be displayed, it should be clearly labeled as generalized context, not a source of truth.
4. Treat Partial Visual Verification as a Supplementary Control, Not a Primary One
Humans cannot reliably compare long hexadecimal strings. Any workflow that depends on “checking a few characters” is already operating below a safe threshold.
Where human verification is required:
Operators should be confirming that a system-selected destination is correct, not manually deciding correctness based on visual similarity.
Operators should never be expected to validate correctness by visual similarity alone.
The goal is not to ask operators to be more careful or to scrutinize longer strings. It is to design workflows where human attention is reserved for exception handling and confirmation, while systems enforce correctness by default.
5. Bonus: proactive adversarial similarity checks
As an additional guardrail, systems can proactively detect risk conditions and potential adversarial actors rather than waiting for human error.
Examples include:
Flagging destination addresses that are similar to known allowlisted addresses.
Alerting when a destination address is newly introduced but visually resembles a high-frequency counterparty.
6. Align controls with realistic adversarial assumptions
Finally, it’s important to internalize the broader lesson: on-chain activity is observable, and operational patterns can be inferred. Controls should assume that repetitive flows, favored destinations, and verification shortcuts are visible to third parties.
This is not to say “you need to be paranoid”. This is acknowledging that normal operations, when exposed to adversarial observation, behave differently than they do in closed systems.
The core takeaway
Address poisoning succeeds not because systems are weak, but because they are designed for convenience in non-adversarial environments. Once an adversary is assumed, visual similarity can no longer be treated as identity, and transaction history can no longer be treated as trust.
The good news is that this class of risk is highly reducible. But it is reduced through policy and workflow changes, not by waiting for better cryptography or more careful operators.
About DigOpp
DigOpp helps institutional clients navigate operational risk in digital assets. Our work spans custody risk assessments (including CCSS audits), digital-asset-specific operational due diligence, counterparty risk analysis, competitive market infrastructure research, and vendor selection.
If you would like to reach out to us, you can email us at info@digopp.group.
Disclaimer
We, Digital Opportunities Group Enterprises, Inc. are not providing investment or other advice. Nothing that we post on Substack should be construed as personalized investment advice or a recommendation that you buy, sell, or hold any security or other investment or that you pursue any investment style or strategy.
Case studies may be included for informational purposes only and are provided as a general overview of our general investment process. We have compiled our research in good faith and use reasonable efforts to include accurate and up-to-date information. In no event should we be responsible or liable for the correctness of any such research or for any damage or lost opportunities resulting from use of our data.
We are not responsible for the content of any third-party websites and we do not endorse the products, services, or investment recommendations described or offered in third-party social media posts and websites.
Nothing we post on Substack should be construed as, and may not be used in connection with, an offer to sell, or a solicitation of an offer to buy or hold, an interest in any security or investment product.
It is important to note that this is outlining the first step in the process: generating the malicious address. There are still the next steps of sending transactions to pollute the victim’s transaction history (which is trivial), and waiting for the victim to send funds to the malicious address (which depends on the victim falling prey to the intended attack).